← View series: ibm ai engineering
~/blog
Deep Neural Network for Breast Cancer Classification

Deep Neural Network for Breast Cancer Classification
Estimated time needed: 30 minutes
This tutorial demonstrates how to build and train a deep neural network for classification using the PyTorch library. The dataset used is the Breast Cancer Wisconsin (Diagnostic) Data Set.
- Deep Neural Network for Breast Cancer Classification
Objectives
After completing this lab you will be able to:
- Use PyTorch to build and train a deep neural network for classification.
Background
What is PyTorch
PyTorch is an open-source machine learning library, developed by Facebook's AI Research lab (FAIR). It is primarily used for applications in areas such as computer vision and natural language processing.
Common Uses of PyTorch
- Developing Deep Learning Models: From standard feed-forward networks to complex neural networks like CNNs and RNNs.
- Research and Experimentation: Facilitates rapid prototyping, which is highly valued in academic and research settings.
- Production Deployment: With the support of TorchServe, PyTorch models can be easily transitioned from research to production environments.
Setup
For this lab, we will be using the following libraries:
pandasfor managing the data.numpyfor mathematical operations.matplotlibfor additional plotting tools.sklearnfor machine learning and machine-learning-pipeline related functions.torchfor building and training the deep neural network.ucimlrepofor loading the dataset.
Installing Required Libraries
%pip install pandas==2.2.2
%pip install numpy==1.26.4
%pip install matplotlib==3.8.0
%pip install scikit-learn==1.5.0
%pip install torch==2.3.1
%pip install ucimlrepo==0.0.7Load the Data
Breast Cancer Wisconsin (Diagnostic)
The Breast Cancer Wisconsin (Diagnostic) dataset is a classic dataset used for classification tasks. It contains 569 samples of breast cancer cells, each with 30 features. The dataset is divided into two classes: benign and malignant. The goal is to classify the breast cancer cells into one of the two classes.
This dataset is free to use and is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
First, we need to load our dataset and take a look at its structure.
from ucimlrepo import fetch_ucirepo
# fetch dataset
breast_cancer_wisconsin_diagnostic = fetch_ucirepo(id=17)
# data (as pandas dataframes)
X = breast_cancer_wisconsin_diagnostic.data.features
y = breast_cancer_wisconsin_diagnostic.data.targets
# print the first few rows of the data
display(X.head())
# print the first few rows of the target
display(y.head())Then let us check the shape of the dataset.
display(f'X shape: {X.shape}')
display(f'y shape: {y.shape}')As we can see, the dataset has 569 samples and 30 features. The target variable is the diagnosis column, which contains the class labels for each sample. The class labels are either 'M' (malignant) or 'B' (benign).
We will then check the distribution of the target variable.
display(y['Diagnosis'].value_counts())Note that the dataset is imbalanced, with more benign samples than malignant samples.
We will now process the data. Randomly choose 200 samples in 'M' (malignant) and 200 samples in 'B' (benign).
import pandas as pd
# Combine features and target into a single DataFrame for easier manipulation
data = pd.concat([X, y], axis=1)
# Separate the two classes
data_B = data[data['Diagnosis'] == 'B']
data_M = data[data['Diagnosis'] == 'M']
# Select 200 samples from each class
data_B = data_B.sample(n=200, random_state=42)
data_M = data_M.sample(n=200, random_state=42)
# Combine the two classes
balanced_data = pd.concat([data_B, data_M])
display(balanced_data['Diagnosis'].value_counts())There are 200 samples in each class, with a total of 400 samples. It means that the dataset is balanced.
We will use 80% of the samples for training and 20% for testing.
Data Preprocessing
Before feeding the data into our neural network, we need to preprocess it. This involves separating the features and labels, splitting the data into training and test sets, and standardizing the feature values.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import torch
# Separate features and targets
X = balanced_data.drop('Diagnosis', axis=1)
y = balanced_data['Diagnosis']
# Convert the targets to binary labels
y = y.map({'B': 0, 'M': 1})
display(X)
display(y)The data will be split into 80% training and 20% test sets.
We then print the shapes of the training and test sets to verify that the data has been split correctly.
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
display(f'X_train shape: {X_train.shape}')
display(f'y_train shape: {y_train.shape}')
display(f'X_test shape: {X_test.shape}')
display(f'y_test shape: {y_test.shape}')Then we standardize the feature values using the StandardScaler from scikit-learn.
Standardizing the data involves transforming the features so that they have a mean of 0 and a standard deviation of 1. This helps in ensuring that all features contribute equally to the result and helps the model converge faster during training.
- Fitting the Scaler: We calculate the mean and standard deviation for each feature in the training set using the
fitmethod of theStandardScaler. - Transforming the Training Data: We apply the standardization to the training data using the
transformmethod, which scales the features accordingly. - Transforming the Test Data: We apply the same transformation to the test data using the same scaler. This ensures that both training and test sets are standardized in the same way.
By standardizing the data, we make sure that each feature contributes equally to the training process, which helps in achieving better performance and faster convergence of the neural network model.
Finally, we convert the NumPy arrays to PyTorch tensors.
from torch.utils.data import DataLoader, TensorDataset
# Standardize the data
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit the scaler on the training data and transform it
X_train = scaler.fit_transform(X_train)
# Transform the test data using the same scaler
X_test = scaler.transform(X_test)
# Convert to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train.values, dtype=torch.long)
y_test = torch.tensor(y_test.values, dtype=torch.long)
# Create DataLoader for training and test sets
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=2, shuffle=False)Build and Train the Neural Network Model
We will define our neural network architecture, specify the loss function and optimizer, and then train the model.
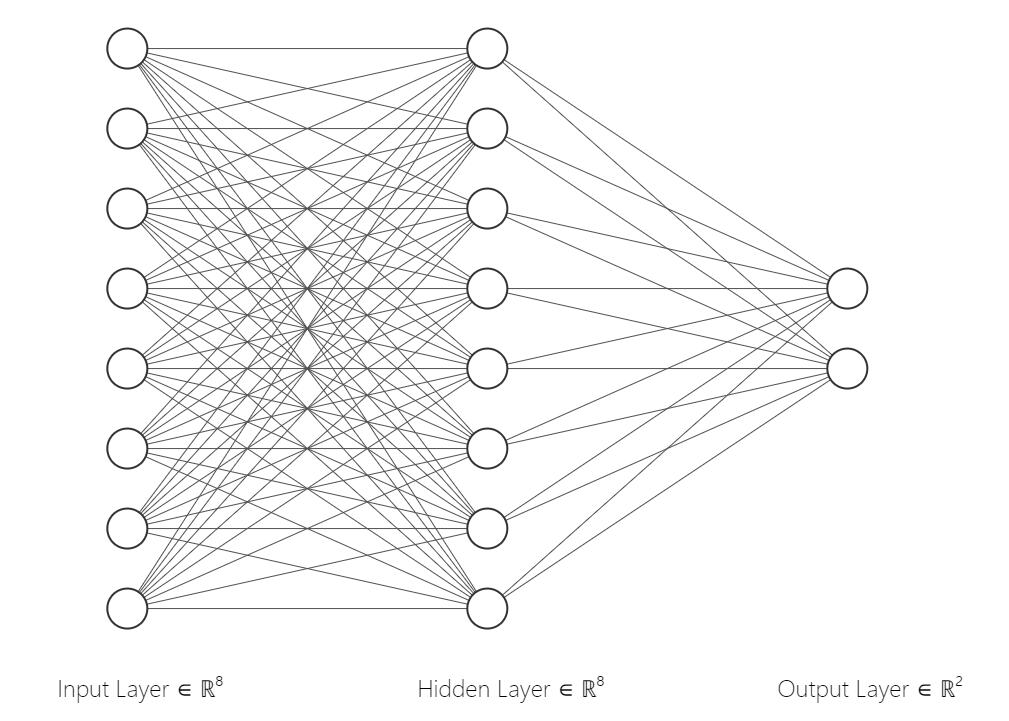
First, we define the neural network architecture using the nn.Module class in PyTorch. Our model consists of an input layer, one hidden layer, and an output layer with 2 neurons corresponding to the 2 classes.
Below is an example of the neural network model, it has 8 neurons in the input layer, 8 neurons in the hidden layer, and 2 neurons in the output layer.
 image
image
import torch.nn as nn
class ClassificationNet(nn.Module):
def __init__(self, input_units=30, hidden_units=64, output_units=2):
super(ClassificationNet, self).__init__()
self.fc1 = nn.Linear(input_units, hidden_units)
self.fc2 = nn.Linear(hidden_units, output_units)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Instantiate the model
model = ClassificationNet(input_units=30, hidden_units=64, output_units=2)Let us visualize the neural network architecture.
print(model)Then we define the loss function and optimizer. We use the CrossEntropyLoss loss function, which is commonly used for multi-class classification problems. The Adam optimizer is used to update the weights of the neural network during training.
import torch.optim as optim
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)Then we can train the model using the training data. We iterate over the training data for a specified number of epochs and update the weights of the neural network using backpropagation.
During training, we calculate the loss at each epoch and print it to monitor the training progress. The loss should decrease over time as the model learns to classify the classes correctly.
Finally, we evaluate the model on the test data to see how well it performs on unseen data.
epochs = 10
train_losses = []
test_losses = []
for epoch in range(epochs):
# Training phase
model.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# Evaluation phase on test set
model.eval()
test_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in test_loader:
test_outputs = model(X_batch)
loss = criterion(test_outputs, y_batch)
test_loss += loss.item()
test_loss /= len(test_loader)
test_losses.append(test_loss)
print(f'Epoch [{epoch + 1}/{epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}')Visualize the Training and Test Loss
Plotting the loss curves helps us understand the training dynamics of our model.
import matplotlib.pyplot as plt
# Plot the loss curves
plt.figure(figsize=(10, 6))
plt.plot(range(1, epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, epochs + 1), test_losses, label='Test Loss', linestyle='--')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss Curve')
plt.legend()
plt.grid(True)
plt.show()Exercises
Exercise 1 - Change to different optimizer: SGD
Stochastic Gradient Descent (SGD) is a widely used optimization algorithm in machine learning and deep learning for training models. It is an iterative method for optimizing a loss function by making small updates to the model parameters in the direction of the negative gradient.
How SGD Works
SGD updates the model's parameters iteratively. The update rule for each parameter $\theta$ is as follows:
$$ \theta = \theta - \eta \cdot \nabla_\theta J(\theta) $$
where:
- $\theta$ represents the model parameters.
- $\eta$ (eta) is the learning rate, which controls the step size of each update.
- $\nabla_\theta J(\theta)$ is the gradient of the loss function with respect to the parameter $\theta$.
PyTorch's torch.optim.SGD
In PyTorch, the torch.optim.SGD optimizer provides several parameters to configure its behavior.
Parameters
-
params:- The model parameters to optimize.
- Typically provided as
model.parameters().
-
lr(learning rate):- A positive float value that controls the step size for each parameter update.
- Example:
lr=0.01.
-
momentum(optional):- A float value that accelerates SGD in the relevant direction and dampens oscillations.
- Example:
momentum=0.9.
-
weight_decay(optional):- A float value representing the L2 penalty (regularization term) to prevent overfitting.
- Example:
weight_decay=0.0001.
-
dampening(optional):- A float value that reduces the effect of the momentum.
- Default is
0.
Example Usage
Here’s how you can use torch.optim.SGD with some of these parameters:
import torch.optim as optim
# Define the SGD optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0001)import torch.optim as optim
model_new_optimizer = ClassificationNet(input_units=30, hidden_units=64, output_units=2)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model_new_optimizer.parameters(), lr=0.001) # Here, change the optimizer to SGD
epochs = 10
train_losses = []
test_losses = []
for epoch in range(epochs):
# Training phase
model_new_optimizer.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model_new_optimizer(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# Evaluation phase on test set
model_new_optimizer.eval()
test_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in test_loader:
test_outputs = model_new_optimizer(X_batch)
loss = criterion(test_outputs, y_batch)
test_loss += loss.item()
test_loss /= len(test_loader)
test_losses.append(test_loss)
print(f'Epoch [{epoch + 1}/{epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}')
import matplotlib.pyplot as plt
# Plot the loss curves
plt.figure(figsize=(10, 6))
plt.plot(range(1, epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, epochs + 1), test_losses, label='Test Loss', linestyle='--')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss Curve')
plt.legend()
plt.grid(True)
plt.show()Click here for Solution
optimizer = optim.SGD(model_new_optimizer.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0001) # Here, change the optimizer to SGDExercise 2 - Change the number of neurons
Define a new neural network architecture with different neurons and see how it affects the model's performance.
# Change the number of hidden units, e.g. 16.
model_new = ClassificationNet(input_units=30, hidden_units=32, output_units=2)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_new.parameters(), lr=0.001)
epochs = 10
train_losses = []
test_losses = []
for epoch in range(epochs):
# Training phase
model_new.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model_new(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# Evaluation phase on test set
model_new.eval()
test_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in test_loader:
test_outputs = model_new(X_batch)
loss = criterion(test_outputs, y_batch)
test_loss += loss.item()
test_loss /= len(test_loader)
test_losses.append(test_loss)
print(f'Epoch [{epoch + 1}/{epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}')
import matplotlib.pyplot as plt
# Plot the loss curves
plt.figure(figsize=(10, 6))
plt.plot(range(1, epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, epochs + 1), test_losses, label='Test Loss', linestyle='--')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss Curve')
plt.legend()
plt.grid(True)
plt.show()Click here for Solution
model_new = ClassificationNet(input_units=30, hidden_units=16, output_units=2)Exercise 3 - Try different dataset - Iris Dataset
Try using the Iris dataset for classification. The Iris dataset is a classic dataset used for classification tasks. It contains 150 samples of iris flowers, each with 4 features. The dataset is divided into three classes, with each class representing a different species of iris flower. The goal is to classify the iris flowers into one of the three classes.
This dataset is free to use and is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
You can load the Iris dataset using the following code:
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
# Extract the features and target variable
X_iris = iris.data
y_iris = iris.targetYou can then preprocess the data, build and train the neural network model, and evaluate its performance on the test set.
# Write your code hereClick here for Solution
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# Load the Iris dataset
iris = load_iris()
# Extract the features and target variable
X_iris = iris.data
y_iris = iris.target
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X_iris, y_iris, test_size=0.2, random_state=42, stratify=y_iris)
# Standardize the data
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Convert to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
y_test = torch.tensor(y_test, dtype=torch.long)
# Create DataLoader for training and test sets
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class IrisNet(nn.Module):
def __init__(self, hidden_units=8):
super(IrisNet, self).__init__()
self.fc1 = nn.Linear(4, hidden_units) # 4 input features for Iris dataset
self.fc2 = nn.Linear(hidden_units, 3) # 3 output classes for Iris dataset
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = IrisNet(hidden_units=8)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 10
train_losses = []
test_losses = []
for epoch in range(epochs):
# Training phase
model.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_train_loss = running_loss / len(train_loader)
train_losses.append(avg_train_loss)
# Evaluation phase on test set
model.eval()
test_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in test_loader:
test_outputs = model(X_batch)
loss = criterion(test_outputs, y_batch)
test_loss += loss.item()
avg_test_loss = test_loss / len(test_loader)
test_losses.append(avg_test_loss)
print(f'Epoch [{epoch + 1}/{epochs}], Train Loss: {avg_train_loss:.4f}, Test Loss: {avg_test_loss:.4f}')
# Plot the loss curves
plt.figure(figsize=(10, 6))
plt.plot(range(1, epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, epochs + 1), test_losses, label='Test Loss', linestyle='--')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss Curve')
plt.legend()
plt.grid(True)
plt.show()Authors
Contributors
© Copyright IBM Corporation. All rights reserved.